UrbanARK
UrbanARK is a joint research project under the US-Ireland Research and Development Programme. UrbanARK explores the use of LiDAR technologies for urban flood risk assessment and communication. Partners of the tri-partite project include University College Dublin (Ireland), Queen's University Belfast (Northern Ireland), and New York University (United States). Together with colleagues at UCD, I am in charge of developing a high-scalability data system for managing and integrating urban spatial data for UrbanARK.
Research outcome to date:

Efficient LiDAR point cloud data encoding for scalable data management within the Hadoop eco-system
This paper has been accepted for presentation at The Next Frontier of Big Data From LiDAR Workshop. The paper introduces a LiDAR point cloud data encoding solution that is compact, flexible, and fully supports distributed data storage within the Hadoop distributed computing environment. The proposed data encoding solution is developed based on Sequence File and Google Protocol Buffers. The proposed solution was benchmarked against a straightforward, naive text encoding implementation using a high-density aerial LiDAR scan of a portion of Dublin, Ireland. The results demonstrated a 6-times reduction in data volume, a 4-times reduction in database ingestion time, and up to a 5 times reduction in querying time.
ARIADNE3D
ARIADNE3D seeks to develop a scalable, high performance and high functionality data storage and exploration system for integrated 3D urban remote sensing data. I have been working on ARIADNE3D since 2017. We use Hadoop, MapReduce, HBase, Spark as the core technologies to develop solutions for management, integration, and analysis of 3D urban data on distributed computing infrastructures.
Research outcome to date:

A Big Data approach for comprehensive urban shadow analysis from airborne laser scanning point clouds
As shadow computation is computationally expensive, most urban shadow analysis tools have to date circumvented the high computational costs by representing urban complexity only through simplified geometric models. The simplification process removes details and adversely affects the level of realism of the ultimate results. In this paper, an alternative approach is presented by utilizing the highest level of detail and resolution captured in the geometric input data source, which is an extremely high-resolution airborne laser scanning point cloud (300 points/m2). To cope with the high computational demand caused by the use of this dense and detailed input data set, the Comprehensive Urban Shadow algorithm is introduced to distribute the computation for parallel processing on a Hadoop cluster. The proposed comprehensive urban shadow analysis solution is scalable, reasonably fast, and capable of preserving the original resolution and geometric detail of the original point cloud data.

Distributed point cloud data analysis algorithms for solar potential simulation
This paper presents a complete point cloud data processing pipeline for simulating solar potential in a distributed computing environment. Unlike most of existing approaches which rely either on 2.5D raster models or overly simplistic, manually-generated, geometric models, the alternative approach proposed in this paper directly exploits the original high-resolution laser scanning data to enable the incorporation of the true, complex, and heterogeneous elements common in most urban areas. To address the resulting computational demands, a distributed data processing strategy is employed that introduces an atypical data partition strategy. The scalability and performance of the approach are demonstrated on a 1.4-billion-point dataset covering more than 2 km2 of Dublin, Ireland. The reliability and realism of the simulation results are rigorously confirmed with (1) an aerial image collected concurrently with the laser scanning, (2) a terrestrial image acquired from an online source, and (3) a four-day, direct solar radiation collection experiment.
Point cloud enrichment and its implications for data service development
This presentation to the OGC Point Cloud DWG highlights the requirement for development of point cloud data access services to off-load heavy data management and data access tasks from point cloud application development. Most of the existing point cloud services are developed for data warehousing and data visualization purposes, which consider only raw point clouds. We envision that point cloud data can also be enriched with computation/simulation data in an incremental manner to be used as a final urban model or a new type of spatial resource for further enrichment. As enriched points clouds become more popular, data service development needs to take into account this more complex type of spatial data.

A 6-dimensional approach to index full waveform LiDAR data in HBase
A scalable solution for handling large full waveform LiDAR datasets is introduced in this paper. The work involves a full waveform database built atop HBase. By combining a 6-dimensional Hilbert spatial code and a temporal index into a compound indexing key, the database system is capable of supporting multiple spatial, temporal, and spatio-temporal queries.
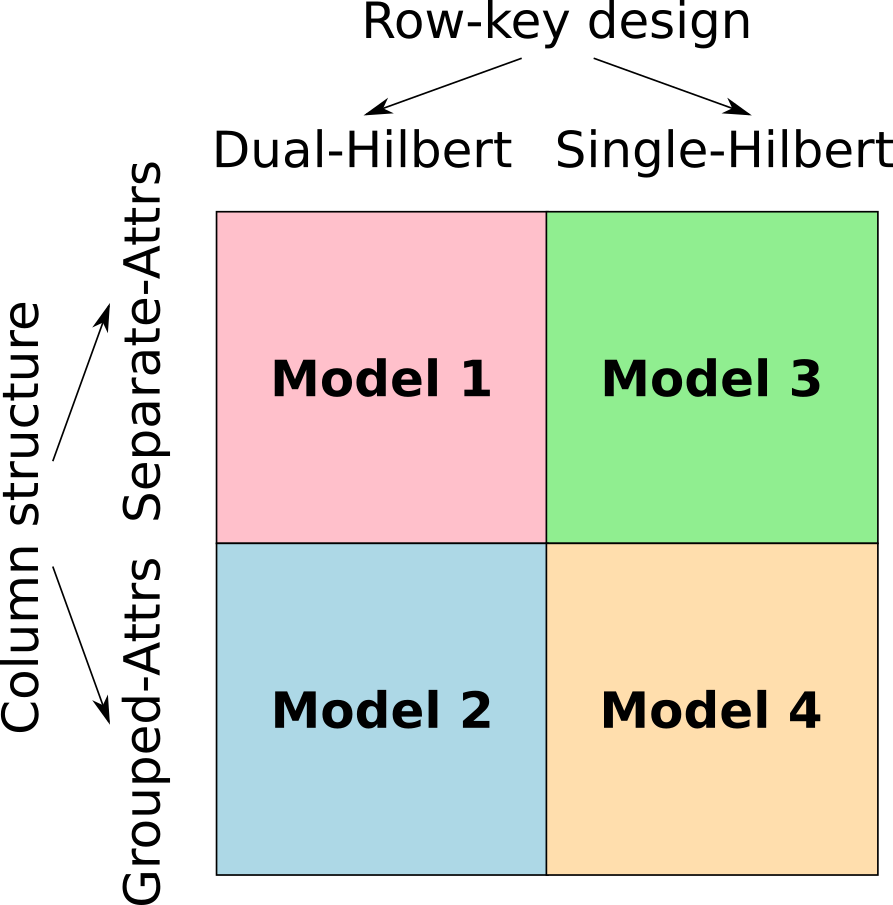
Point cloud storage and indexing in Hadoop HBase
This paper presents our investigation of 4 different data models for storage of point clouds in HBase - the distributed, key-value data store within the Hadoop ecosystem. The paper shares the lessons learned and reassesses several well-known point cloud management techniques in the context of the key-value database.
RETURN
RETURN (Rethinking Tunnelling in Urban Neighbourhoods) is an EU-funded ERC project aiming to create an automated pipeline from aerial laser scanning to city-scale computational modelling. I joined RETURN in 2013 as a PhD candidate at UCD School of Civil and Environmental Engineering.
My contributions to RETURN include:
High resolution aerial LiDAR and photogrammetry datasets of Dublin City
This aerial data collection acquired in March 2015 include an exclusively dense airborne LiDAR dataset (discrete and full waveform at more than 300 pulses/m2), and a photogrammetry dataset (oblique and multi-spectral nadir imagery data). I was tasked with evaluating and indexing the data records for publishing on the NYU Spatial Data Repository.
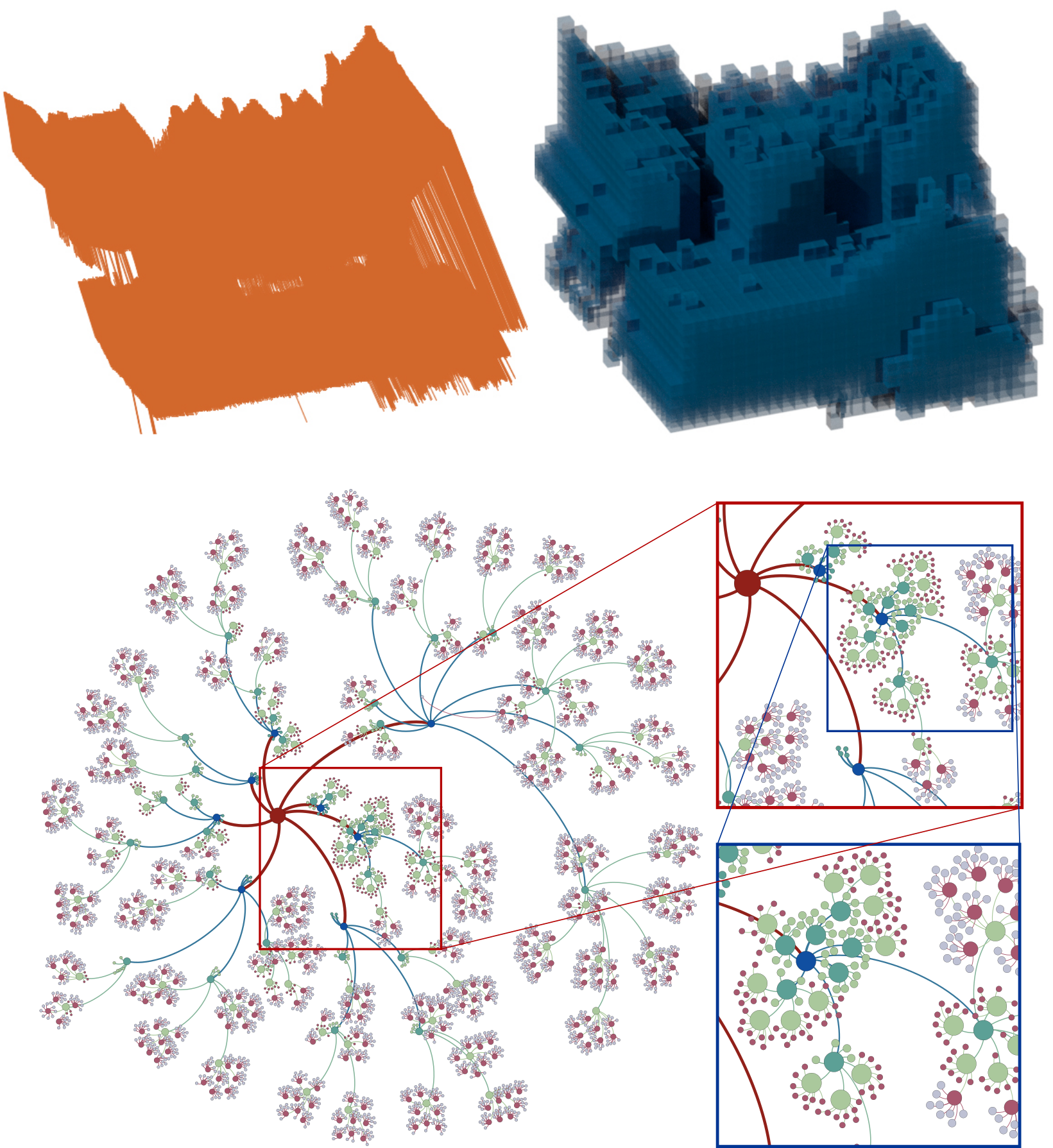
A fast, octree-based point cloud segmentation algorithm
This research published on ISPRS integrates an octree spatial structure with a region growing segmentation algorithm to accelerate the data processing speed without significantly compromising the output accuracy. The octree structure is used in this paper to: (1) organize the point data (i.e. indexing); (2) construct a rasterised representation of input point cloud (i.e. a simplification); and (3) define groups of neighboring points for feature estimation.
A spatio-temporal index for aerial full waveform laser scanning data
This paper published on ISPRS presents an approach for storing and indexing full waveform laser scanning data in a relational database environment, while considering both the spatial and the temporal dimensions of that data. The purpose of data indexing is, of course, to make the data searchable or accessible. Two indexing concepts (i.e. simple index and hybrid index) were implemented and evaluated. The implementations were based on Data Cartridges, an Oracle framework for developing software plugins to extend the database's behaviours (i.e. full waveform indexes and spatio-temporal queries).
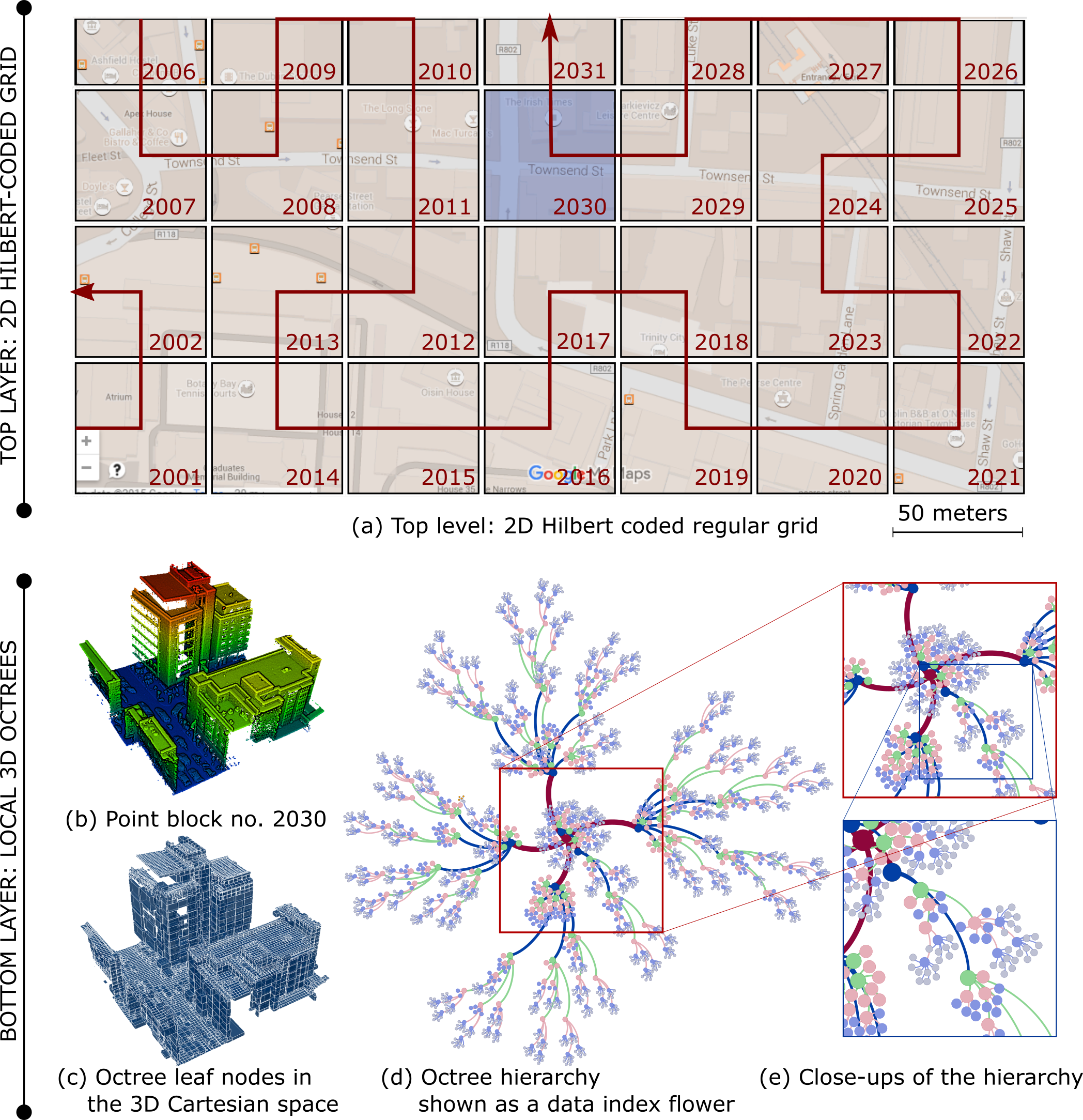
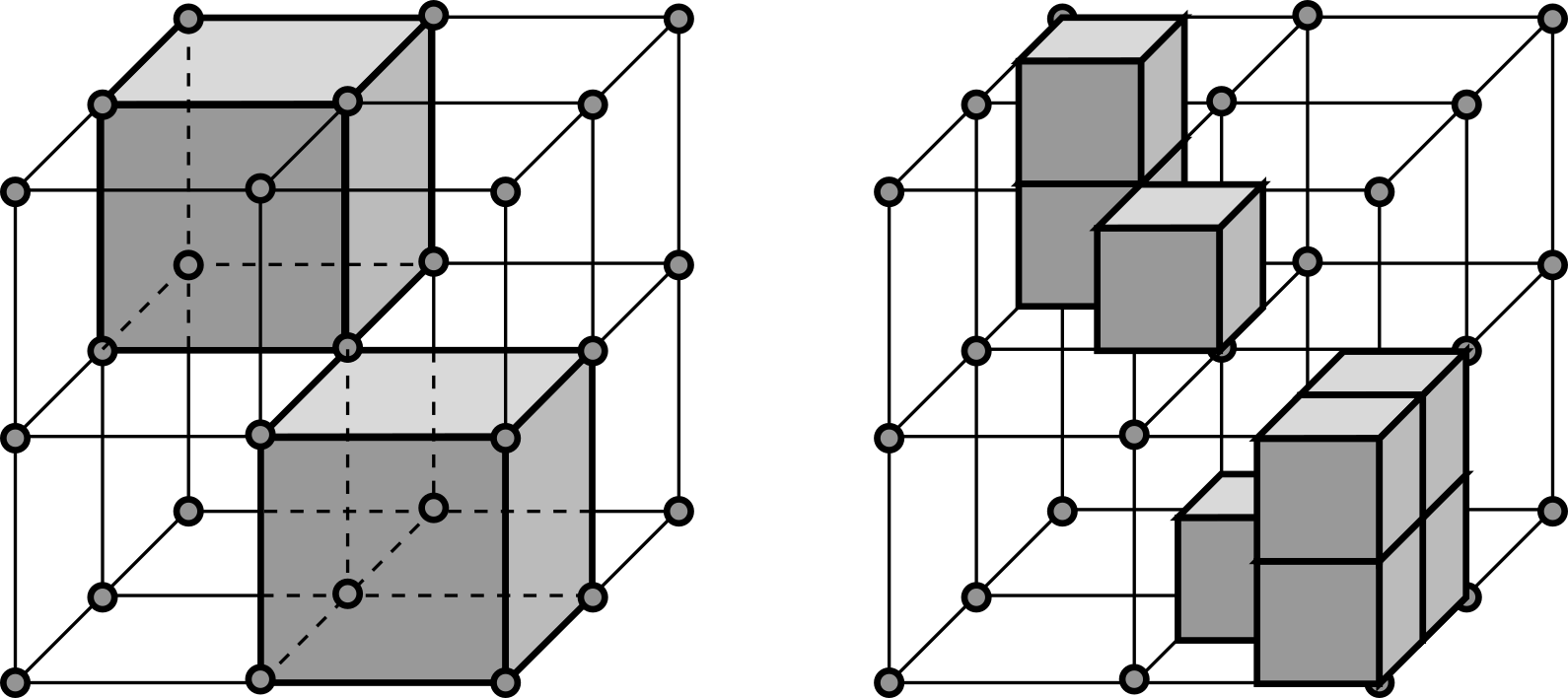
Combining 2D and 3D indexing for efficient airborne LiDAR data management
This work proposes an approach for the management of discrete LiDAR point clouds in a relational database. The approach uses multiple data indexing layers: a top layer with two-dimensional, Hilbert coded, rectangular grid and a bottom layer with multiple, in-memory, 3D octrees. The hybrid indexing mechanism is aimed to speed up spatial queries. In addition, the index is able to support a region growing algorithm running on the server side.
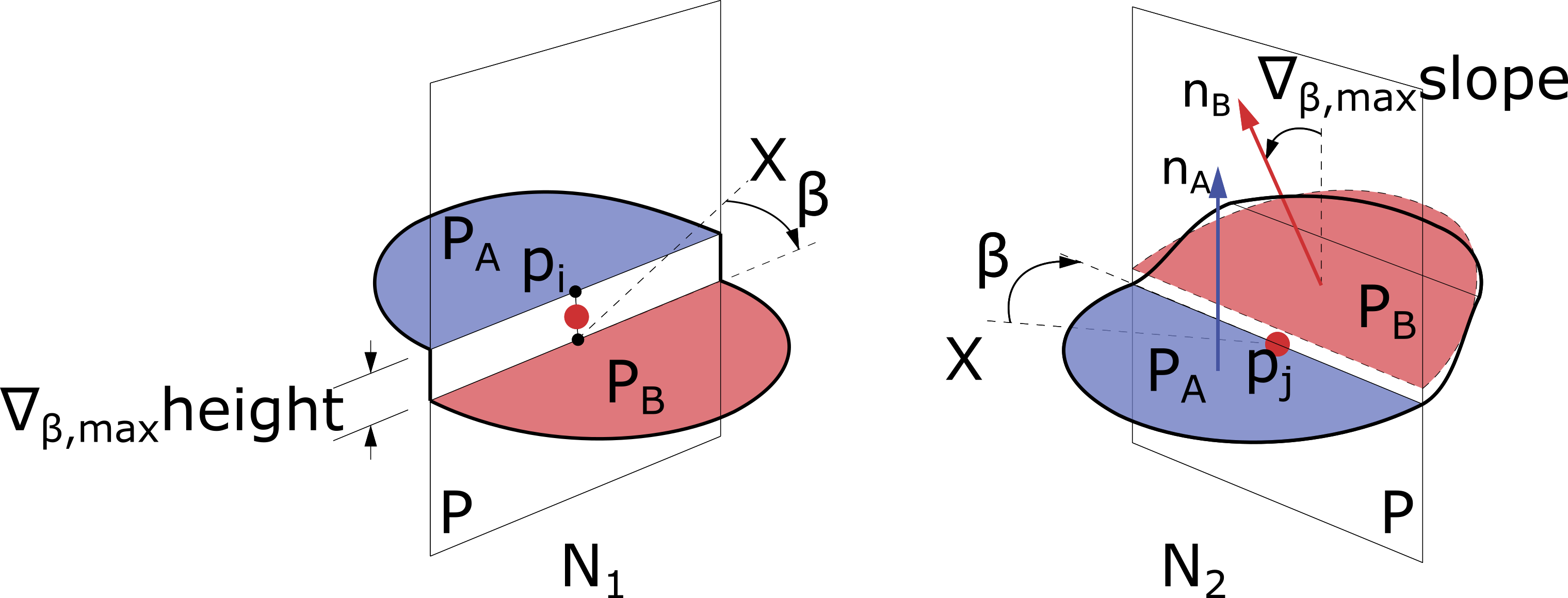
Detecting road segments from a fusion of high-resolution aerial LiDAR point clouds and imagery data
This work, winning the First Prize in the 2015 Data Fusion Contest, introduces a strategy for detecting roads from a fusion of a dense LiDAR dataset and a high resolution imagery dataset. The data processing strategy is based on the high variations of slope and elevation along road curbs. In addition, the paper describes a complete out-of-core data pipeline, including data fusion, management, classification, and processing, which is a robust workflow for analysing a large amount of airborne LiDAR data.